
Example tasks across Bridge V2, SIMPLER, and LIBERO.
RoboMonkey
Scaling Test-Time Sampling and Verification
for Vision-Language-Action Models
Embodied Test-Time Scaling Law
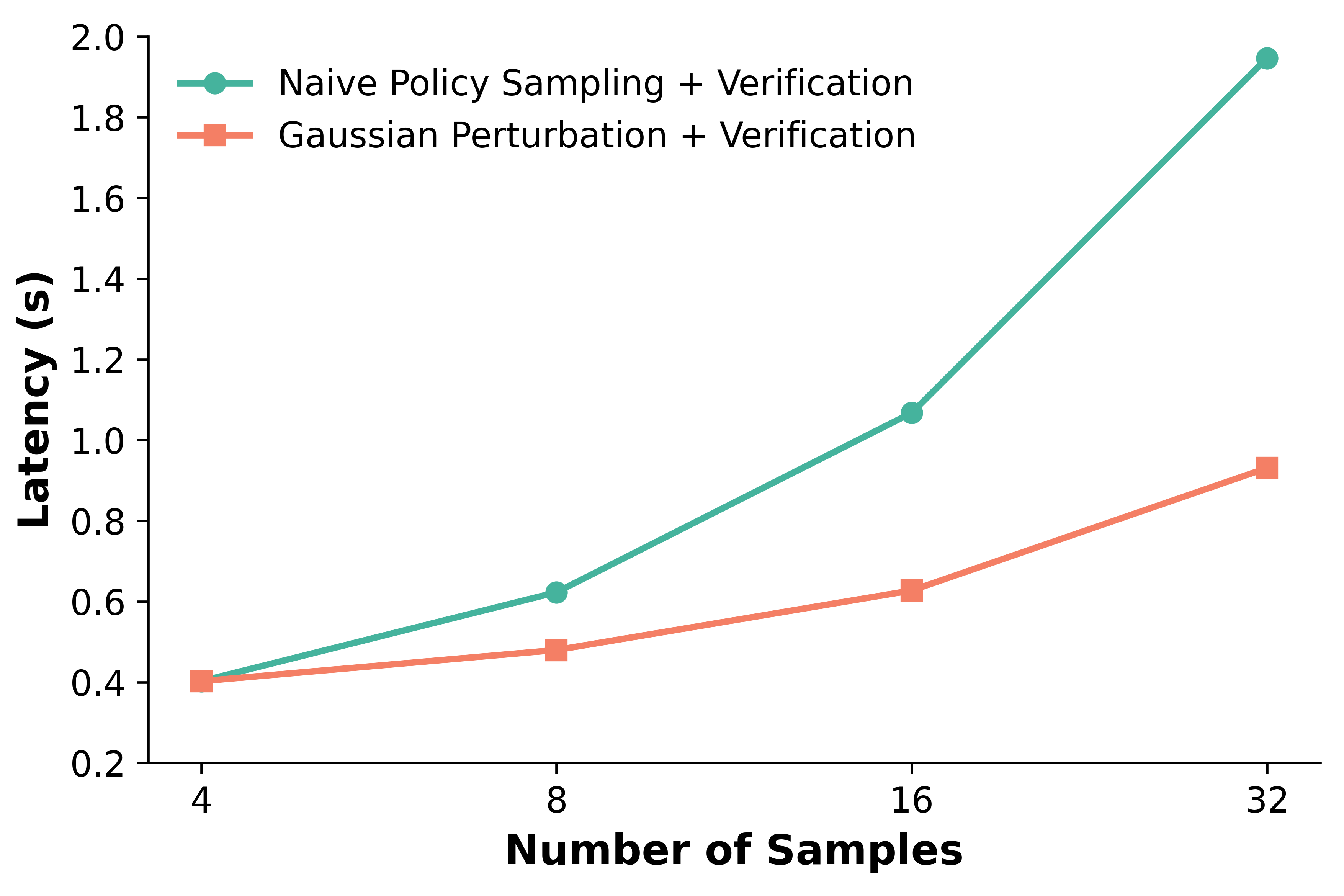
We observe that action error consistently decreases as we scale the number of generated actions across multiple sampling approaches, assuming the presence of an oracle verifier. Repeatedly sampling actions from robot policies, applying Gaussian perturbation to a few sampled actions, and even random sampling of action tokens all outperform single-attempt OpenVLA.
We also find that the relationship between action error and the number of samples generated through Gaussian Perturbation follows an approximate power law across a range of VLA models, including CogACT, Octo, OpenVLA, and SpatialVLA.
For power law fitting, we model the logarithm of action error e as a function of the number of samples: log(e) ≈ log(a) + b * log(k).
Approach
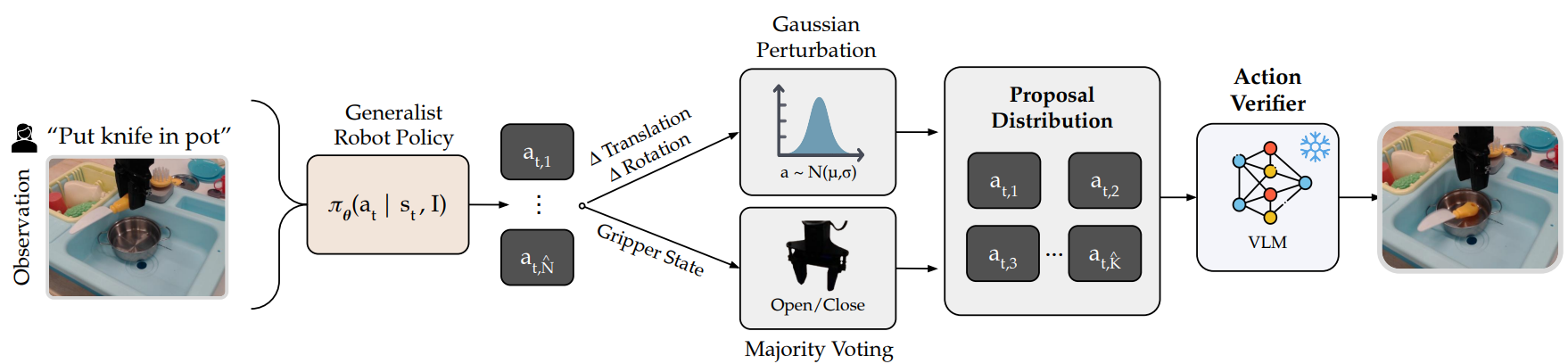
Stage 1: Training the Action Verifier: Given an imitation learning dataset, we sample N candidate actions per state from a generalist robot policy, and apply clustering to reduce them to K representative actions. We construct synthetic action comparisons and assign preferences based on the RMSE between each sampled action and the ground-truth action. This synthetic preference dataset is then used to fine-tune a VLM-based action verifier.

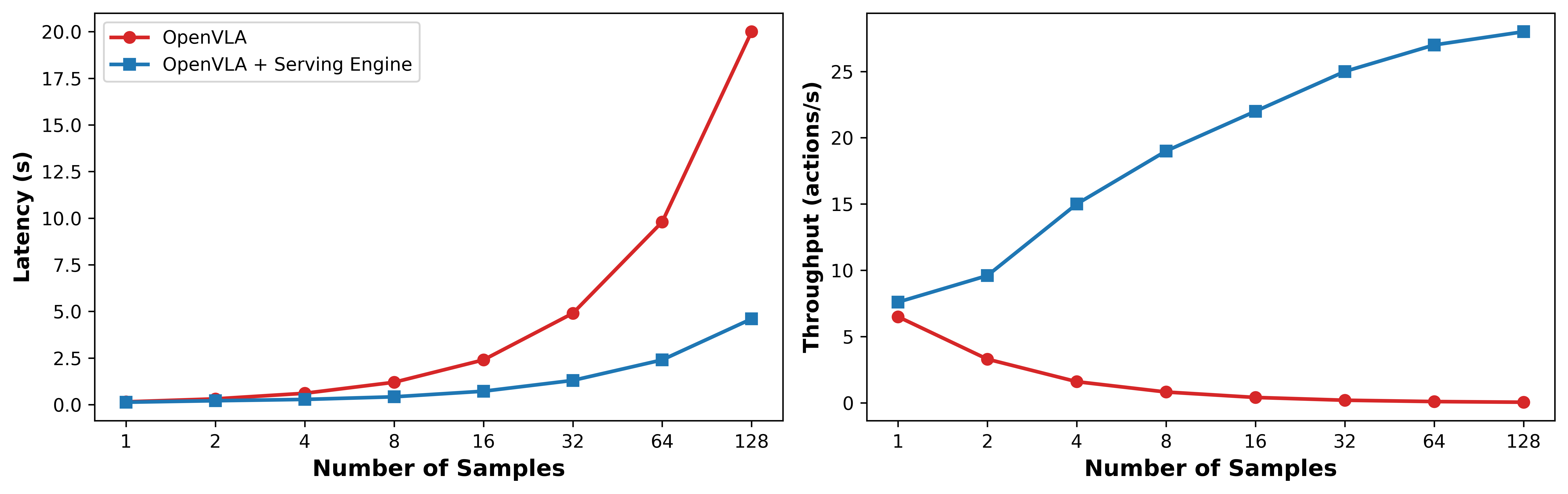
Stage 2: Scaling Test-Time Compute: At deployment, we sample N̂ initial actions from the generalist robot policy based on the given task instruction and observation. We fit a Gaussian distribution to the translation and rotation components of these actions, and use majority voting to determine the gripper state. This creates an action proposal distribution from which we can efficiently sample candidate actions with negligible overhead. Finally, we use the fine-tuned VLM-based verifier to evaluate these K̂ candidate actions and select the optimal action.
Experiments
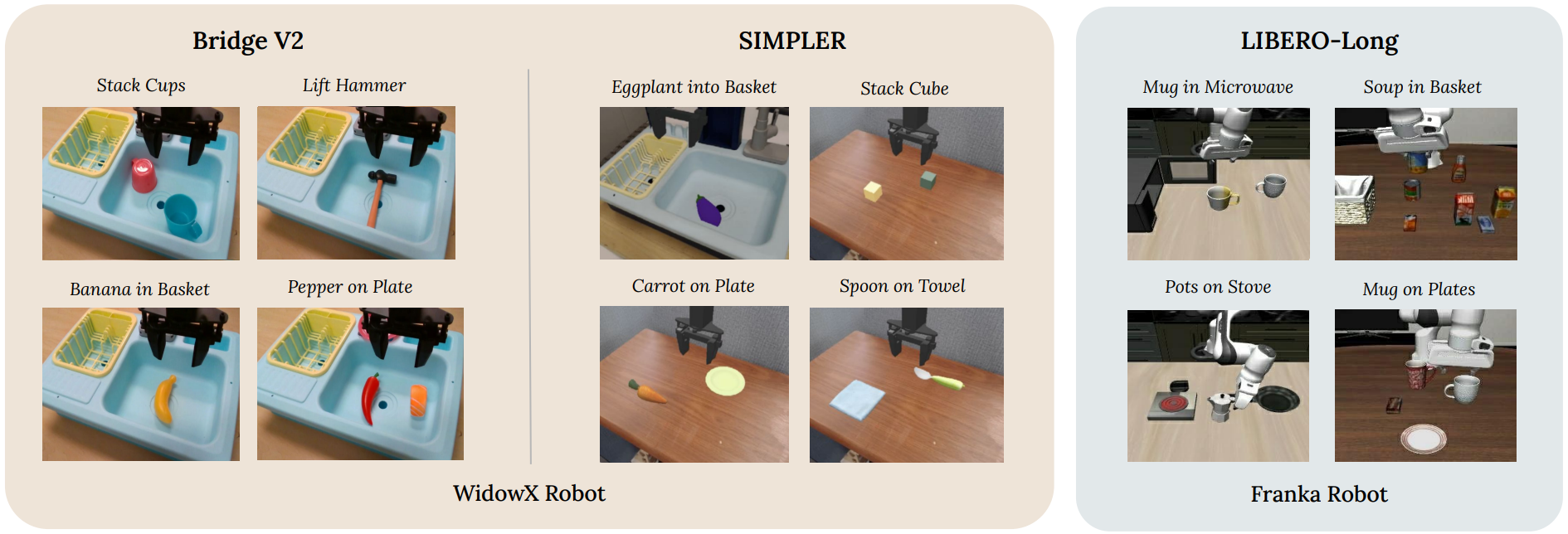
① Bridge V2
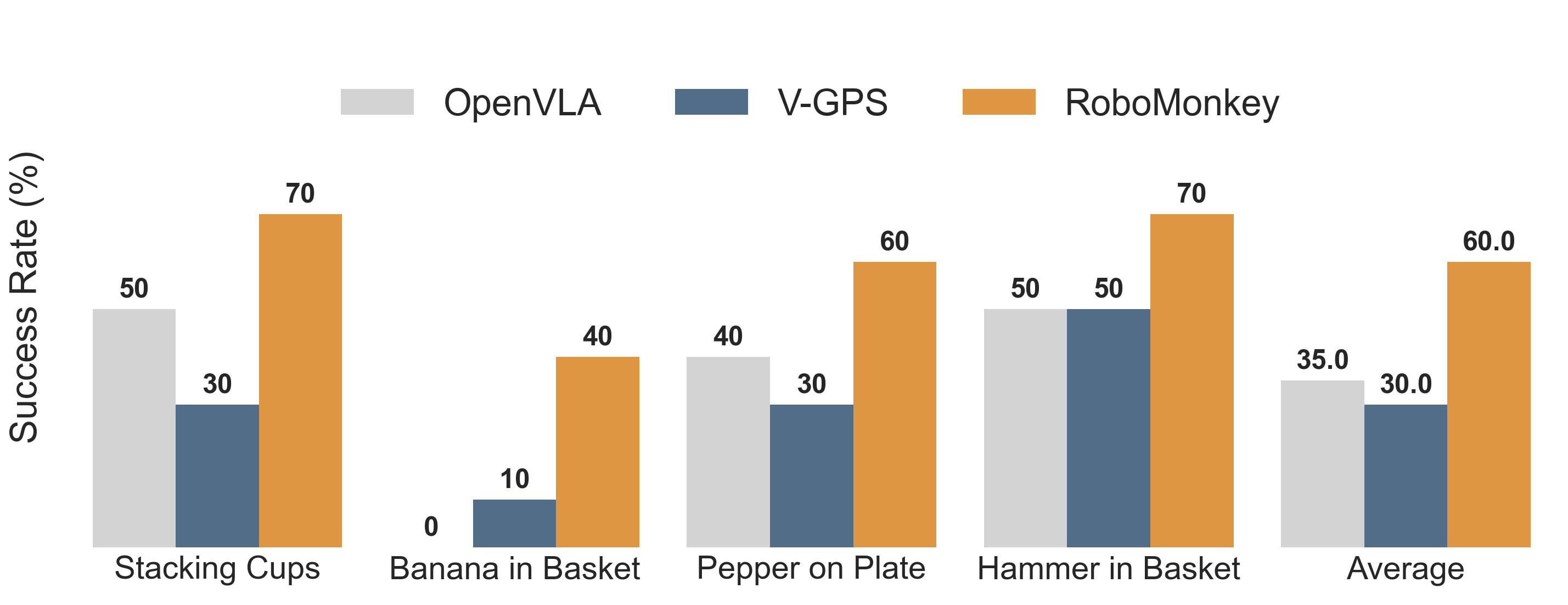
Scaling test-time compute leads to substantial improvements on OOD generalization tasks, achieving a 25% absolute improvement
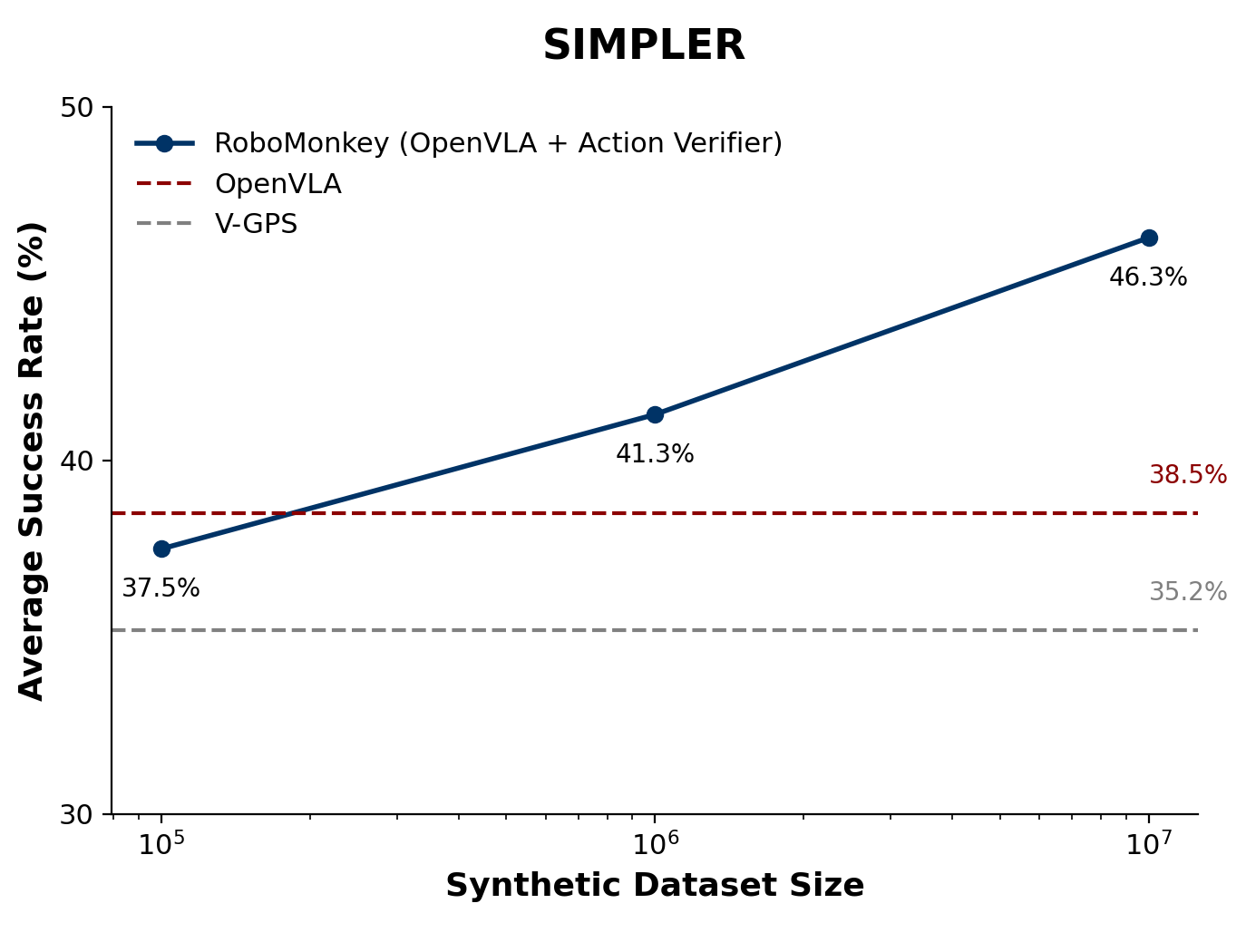
② SIMPLER
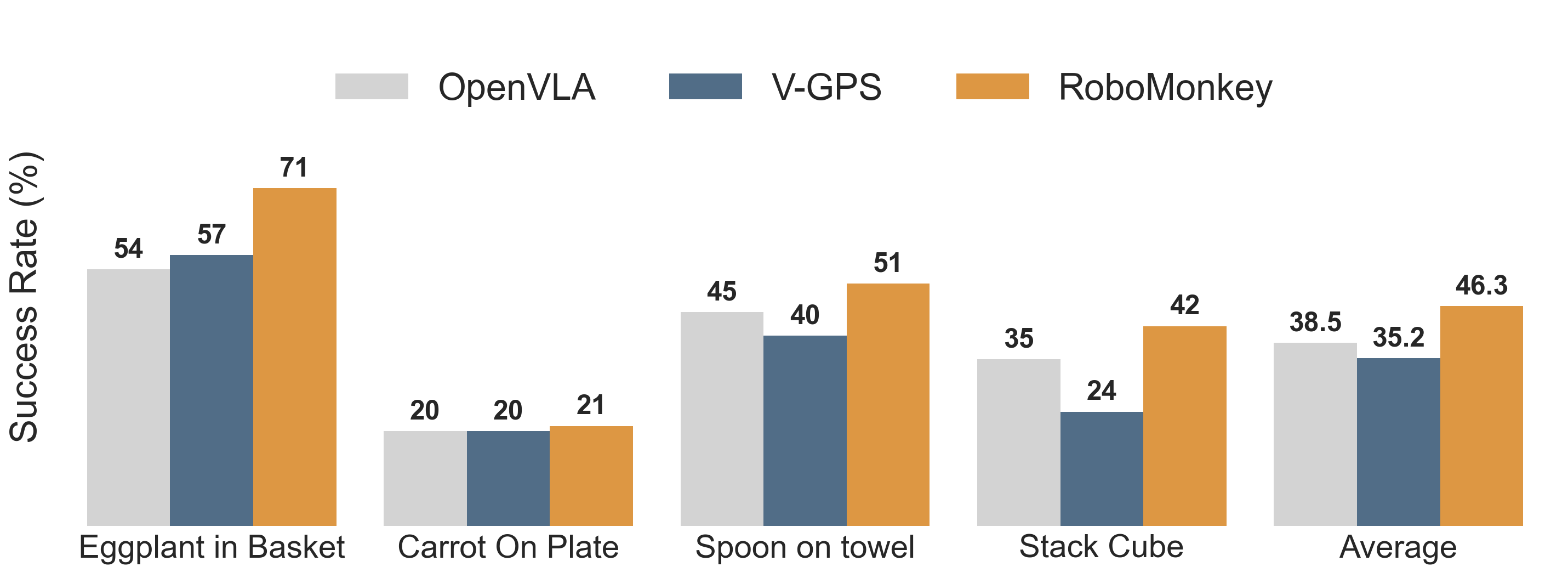
RoboMonkey improves the precision of generalist robot policies in the SIMPLER environment, leading to 9% higher average success rate on in-distribution tasks
③ LIBERO-LONG
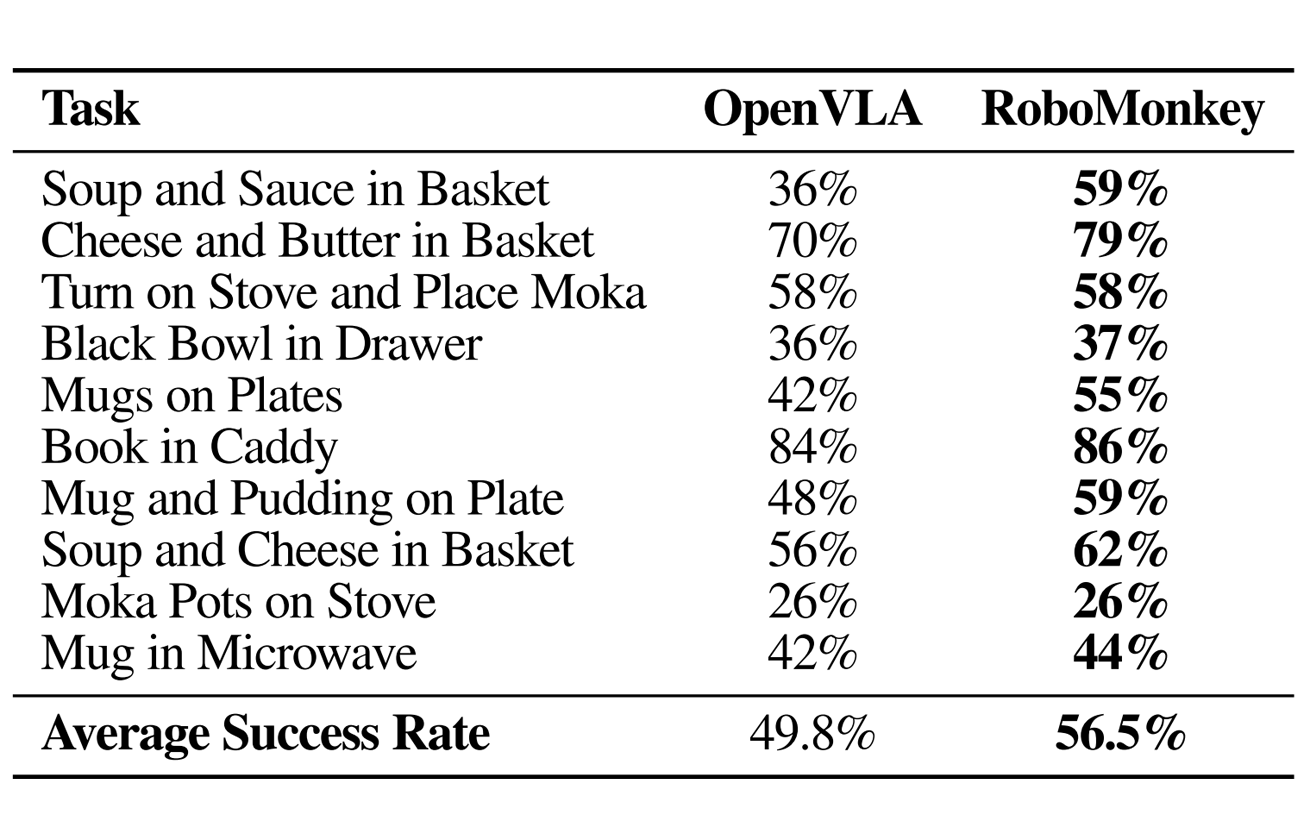
Fine-tuning both OpenVLA and RoboMonkey action verifier results in 7% improvement in average success rate compared to simply fine-tuning OpenVLA on LIBERO-Long